|
 
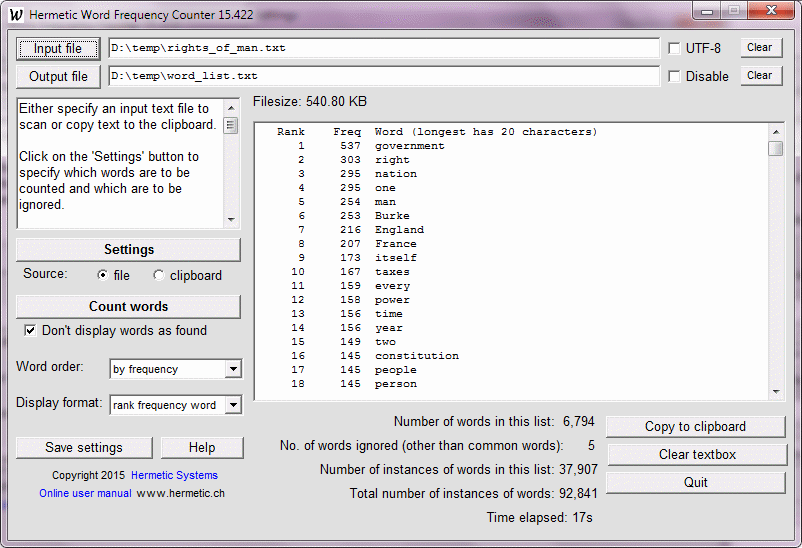
 This software scans a text file (in this sense HTML and XML files are 'text' files) with text encoded via ANSI or UTF-8 and counts the frequencies of different words. The words which are found and displayed can be ordered alphabetically or by frequency. Characters which can appear in words can be specified, so the program can be told to allow or disallow words with numerals, hyphens, apostrophes, underscores or colons, to ignore words which are short or which occur infrequently, to treat upper/lower case as significant or not, and to ignore words (e.g., common words such as 'this') contained in a specified file. This software may be used with text in languages other than English, in particular, with French, German, Italian, Spanish and Portuguese text. Language of the text is detected automatically and the corresponding 'common words' file (with words to be ignored) is optionally loaded. Results can be written to an output file and can then be read into Excel for further processing. There is also an Advanced Version which does everything the standard version does, can count words matching certain patterns, and is able to scan not just one file but all files in a folder, and optionally in all subfolders, and to return a single report on the frequencies of words in all files scanned. This software scans a text file (in this sense HTML and XML files are 'text' files) with text encoded via ANSI or UTF-8 and counts the frequencies of different words. The words which are found and displayed can be ordered alphabetically or by frequency. Characters which can appear in words can be specified, so the program can be told to allow or disallow words with numerals, hyphens, apostrophes, underscores or colons, to ignore words which are short or which occur infrequently, to treat upper/lower case as significant or not, and to ignore words (e.g., common words such as 'this') contained in a specified file. This software may be used with text in languages other than English, in particular, with French, German, Italian, Spanish and Portuguese text. Language of the text is detected automatically and the corresponding 'common words' file (with words to be ignored) is optionally loaded. Results can be written to an output file and can then be read into Excel for further processing. There is also an Advanced Version which does everything the standard version does, can count words matching certain patterns, and is able to scan not just one file but all files in a folder, and optionally in all subfolders, and to return a single report on the frequencies of words in all files scanned.
Related Searches: word, hermetic, frequency, counter, counting, count, number, text, program, occurrences, file, clipboard, english, german, french, italian, frequencies, xml, html
Recent Changes: Added support for files with mixed ASCII/non-ASCII text.
Install Support: Install and Uninstall
Supported Languages: English
Additional Requirements: Not Established
|