The purpose of eDoc Data Extractor is to extract text from a searchable PDF in a batch process, and use this text to rename the file and optionally create a CSV file. The searchable PDFs can come from an application or the output from scanning \ OCR programs.
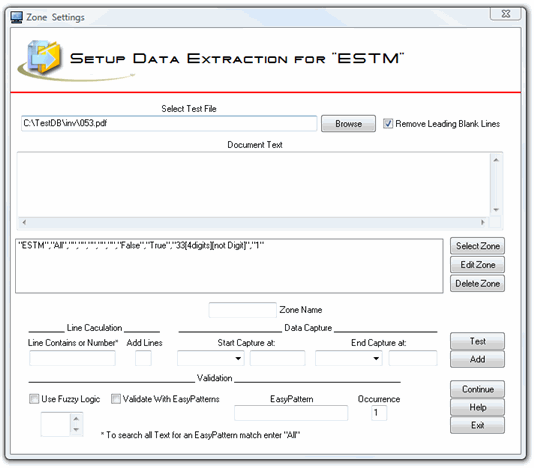
Since most of the time it will be used to process scanned files with OCR content and OCR is not perfect, the program was designed to validate the captured data with rules. It has also been designed to be flexible in the area that it captures as scanned, OCR'd files are not always formatted exactly the same. In other words one will have a value on line one and the next file may have the same value on line two.
Since the line will most likely always have a static value such as "Invoice Number" it can be used to locate the line to parse. If it does not have a static value lines can be added to a line that does have a static value. So it can be set to look for a line that has "Invoice" add two lines and capture the first 30 characters. (perhaps a company name).
Ideally eDoc Data Extractor would be used to capture a single unique value or two, create a CSV file and have a user supplied program connect to a database and validate the captured data. eDoc Data Extractor can also be used as a capture function for eDoc Viewer as the CSV file can be loaded saving the user time in manually entering data.